เมื่อทราบค่าของ Attribute หนึ่ง จะทำให้ สามารถทราบค่าของ Attribute อื่น ๆ ในทูเพิล (tuple) เดียวกันของ Relation ได้
โดยมีทั้งหมด 3 รูปแบบ
- FD (Functional dependency)
- ความหมาย: การที่ค่าของ Attribute ตั้งแต่หนึ่ง Attribute หรือมากกว่า สามารถประกอบกันแล้วสามารถระบุค่าของ Attribute อื่น ๆ ภายใน Tuple เดียวกัน (บรรทัดเดียวกัน) ของ Relation นั้นได้
- ตัวระบุค่าเรียกว่า Determinant
- ตัวที่ถูกระบุค่าเรียกว่า Dependent
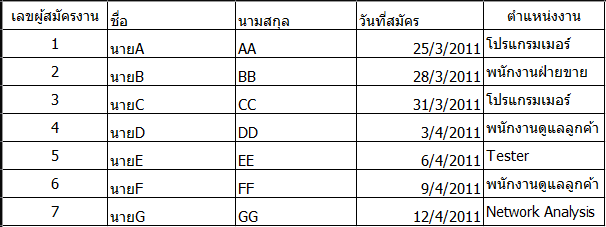
- หากทราบค่า เลขผู้สมัครงาน (ที่เป็นค่า Determinant) จะสามารถทราบค่าของ ตำแหน่งงาน (ที่เป็นค่า Dependent) ได้
- ในทางกลับกัน หากทราบค่า ตำแหน่งงาน (ที่เป็นค่า Dependent) อาจไม่สามารถระบุ
เลขผู้สมัครงาน (ที่เป็นค่า Determinant) ที่แน่ชัดได้
- กรณีมีตัวระบุค่ามีเพียงหนึ่ง Attribute และตัวถูกระบุค่ามีมากกว่าหนึ่ง Attribute
- เลขผู้สมัครงาน -> ชื่อ
- เลขผู้สมัครงาน -> นามสกุล
- (เขียนรวม ๆ) เลขผู้สมัครงาน -> ชื่อ, นามสกุล, วันที่สมัคร, ตำแหน่งงาน
- กรณีมีตัวระบุค่ามีมากกว่าหนึ่ง Attribute และตัวถูกระบุค่ามี 1 Attribute
- ชื่อ, นามสกุล -> เลขผู้สมัครงาน
- Fully functional dependency คือความสัมพันธ์ระหว่าง Attribute แบบทั้งหมด
- Determinant มีขนาดเล็กที่สุด และสามารถระบุค่าของ Attribute อื่น ๆ ที่เป็น Dependent ได้อย่างชัดเจน
- Partial dependency และ Transitive dependency
- ความหมายของ Partial dependency: เมื่อใน Relation หนึ่งนั้นมีคีย์หลัก (Primary Key) เป็นคีย์ผสม และ Attribute บางส่วนของคีย์หลักสามารถระบุค่าของ Attribute อื่น ๆ ใน Tuple (บรรทัดเดียวกัน) เดียวกันได้
- ความหมายของ Transitive dependency: เมื่อใน Relation หนึ่งนั้นมี Attribute ที่ไม่ใช่คีย์หลักแต่สามารถระบุค่าของ Attribute อื่น ๆ ใน Tuple (บรรทัดเดียวกัน) เดียวกันได้
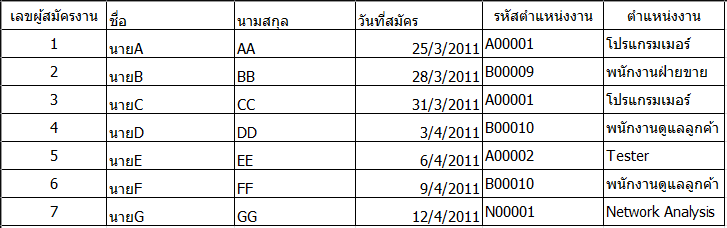
- จะเห็นว่าหากใช้ Primary Key ของเลขผู้สมัครงาน จะสามารถเรียกข้อมูลได้ทุก Field

- หากใช้รหัสตำแหน่งงาน จะสามารถระบุชื่อของตำแหน่งงานได้

- จะเห็นว่าหากใช้ Primary Key ของเลขผู้สมัครงาน จะสามารถเรียกข้อมูลได้ทุก Field
- ความแตกต่างของ Partial dependency และ Transitive dependency คือ Partial dependency ตัวที่เชื่อมกันเป็น primary Key Transitive dependency ตัวที่เชื่อมกันไม่เป็น Primary Key แต่สามารถระบุเอกลักณ์ได้
- Join dependency
- ความหมาย: Relation นั้น ๆ สามารถจำแนกออกเป็นรีเลชันย่อยได้ และเมื่อนำ Reloation ย่อยที่จำแนกออกมาเหล่านั้นมารวมกันจะต้องได้ Relation กลับไปเหมือนเดิม
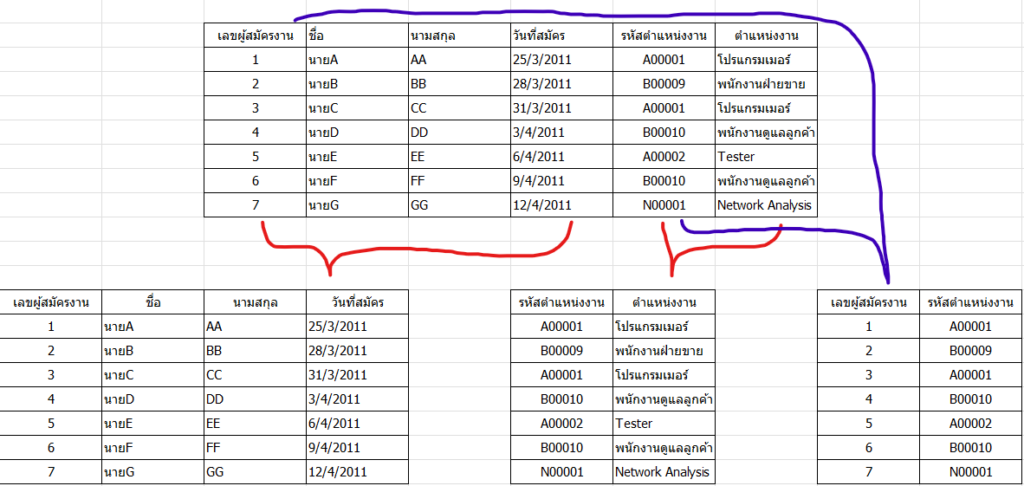
- ความหมาย: Relation นั้น ๆ สามารถจำแนกออกเป็นรีเลชันย่อยได้ และเมื่อนำ Reloation ย่อยที่จำแนกออกมาเหล่านั้นมารวมกันจะต้องได้ Relation กลับไปเหมือนเดิม
รูปแบบที่เป็นบรรทัดฐานขั้นที่ 1 (First Normal Form : 1 NF)
คุณสมบัติ: ทุกAttribute ในแต่ละTuple มีค่าของข้อมูลเพียงค่าเดียว (ทุกอย่างกองอยู่รวมกัน)
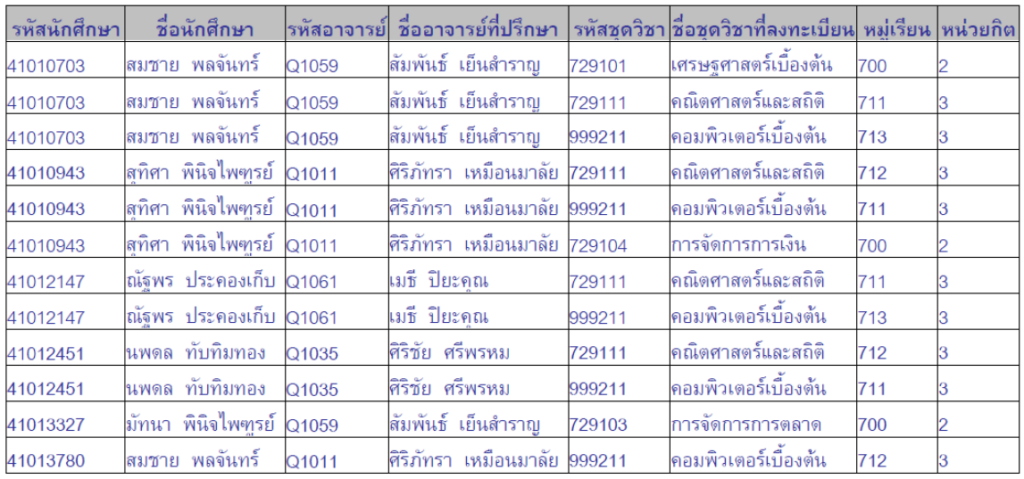
รูปจาก: Link
รูปแบบที่เป็นบรรทัดฐานขั้นที่ 2 (Secoend Normal Form : 2 NF)
คุณสมบัติ: อยู่ในรูปแบบบรรทัดฐานขั้นที่ 1 และไม่มี Partial dependency เกิดขึ้น

จากนั้นแบ่งออกเป็น Relation ย่อย ๆ
โดยจะได้เป็น Relation ข้อมูลนักศึกษา Relation, ข้อมูลการลงทะเบียน และ Relation ชุดวิชา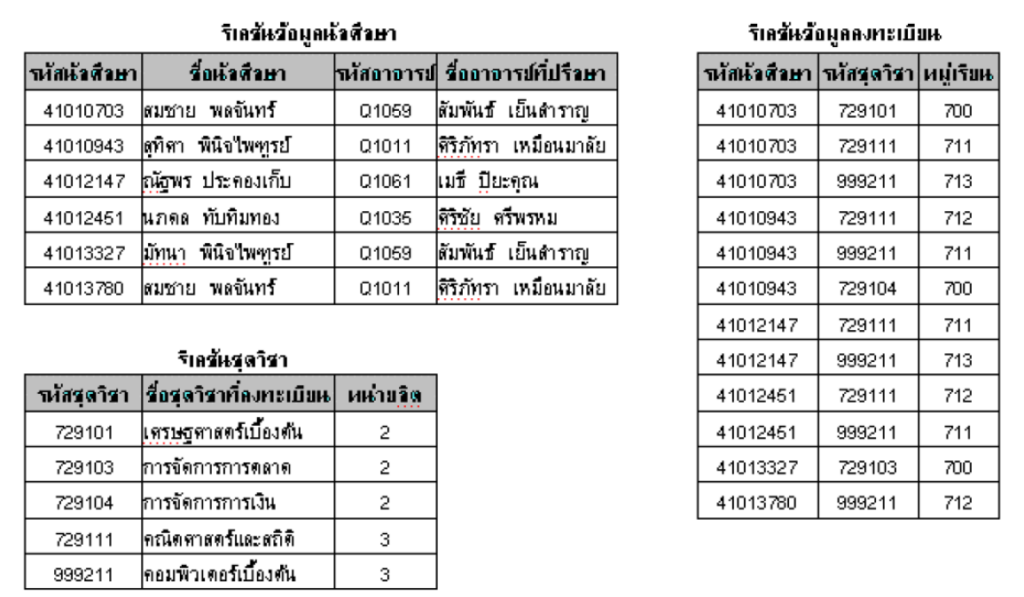
รูปจาก: Link
รูปแบบที่เป็นบรรทัดฐานขั้นที่ 3 (Third Normal Form : 3 NF)
คุณสมบัติ: อยู่ในรูปแบบบรรทัดฐานขั้นที่ 2 และไม่มี Transitive dependency เกิดขึ้น
จากขั้นที่ 2 NF จะเห็นได้ว่า Relation ข้อมูลนักศึกษา มีข้อมูลรหัสอาจารย์และชื่ออาจารย์ที่มีความสัมพันธ์กัน ให้แยกออกมาเป็น Relation ย่อย
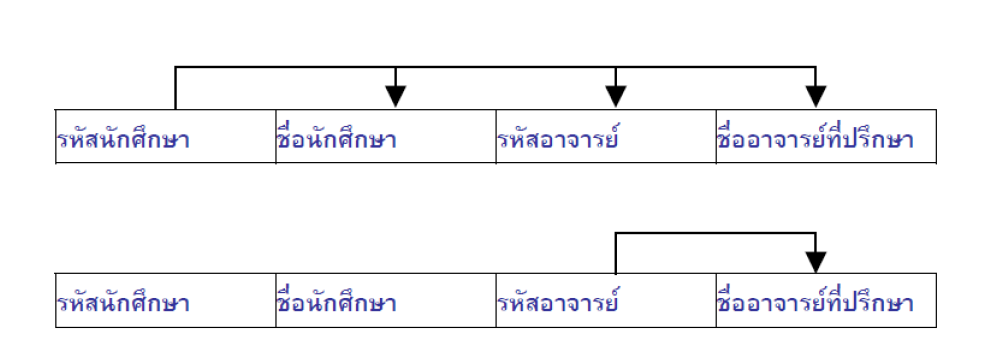
จะได้ Relation อาจารย์ที่ปรึกษา กับ Relation นักศึกษา เพิ่มขึ้นมา
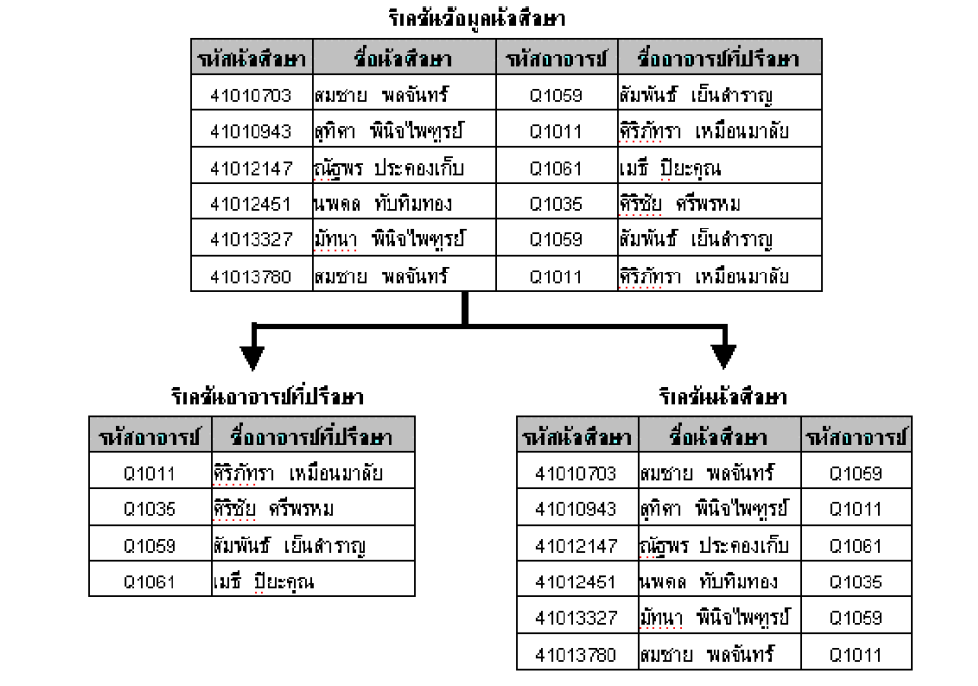
รูปจาก: Link
และนอกจากนี้ จะเห็นได้ว่ามีอีก Relation คือ ชุดวิชาที่สามารถแบ่งออกมาได้อีก
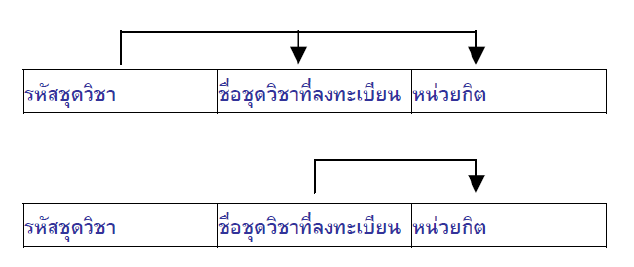
จะได้ Relation รหัสวิชา-ชุดวิชา กับ Relation ชุดวิชา-หน่วยกิต เพิ่มเข้ามา
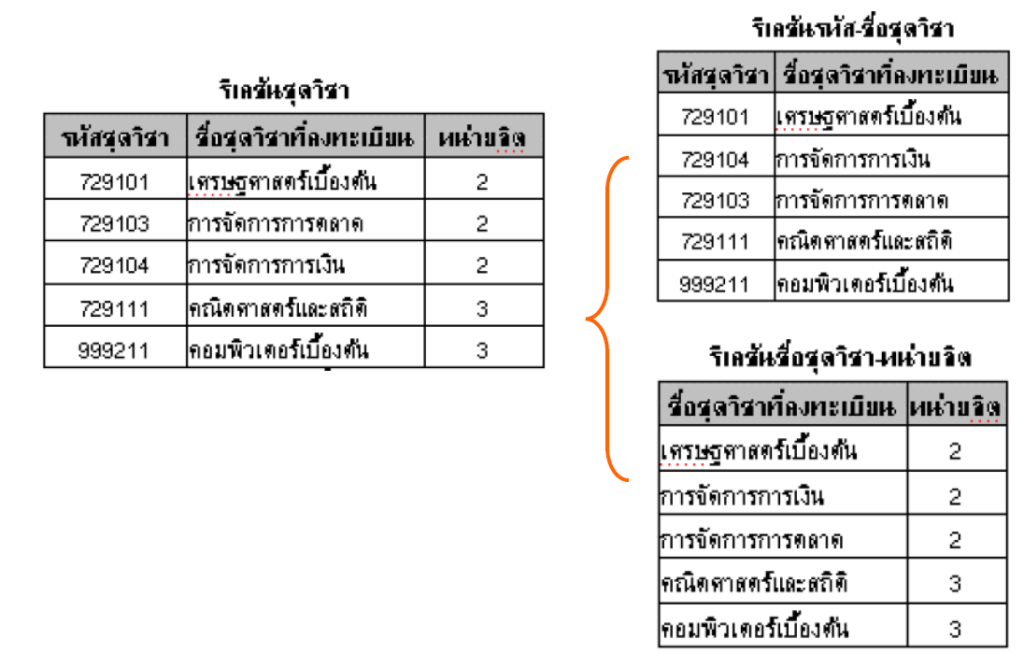
รูปจาก: Link
Over normalization การจำแนก Relation ย่อยมากเกินไป อาจทำให้ใช้เสียเวลาในการค้นหาข้อมูลมากขึ้น

