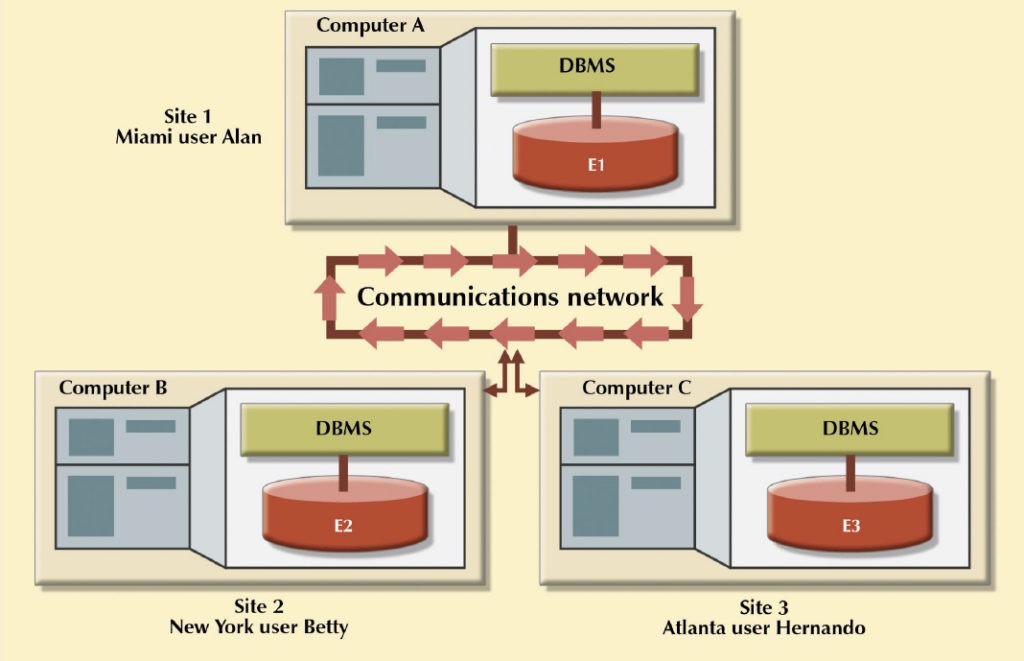
สถาปัตยกรรมระบบฐานข้อมูลแบบกระจาย
- การกระจายข้อมูลไปเก็บไว้หลาย ๆ เครื่อง เพื่อเพิ่มประสิทธิภาพในการประมวลผล เพิ่มความน่าเชื่อถือ เพื่อกระจายการใช้งานข้อมูล
- เชื่อมต่อเข้าด้วยกันผ่านระบบเครือข่าย
- แต่ละที่จะมีระบบจัดการฐานข้อมูลเป็นของตนเอง และสามารถที่จะทำงานได้ด้วยตนเอง หรือร่วมกันทำงานก็ได้ โดยที่คอมพิวเตอร์แต่ละเครื่อง จะเรียกว่า ไซต์ หรือ โหนด
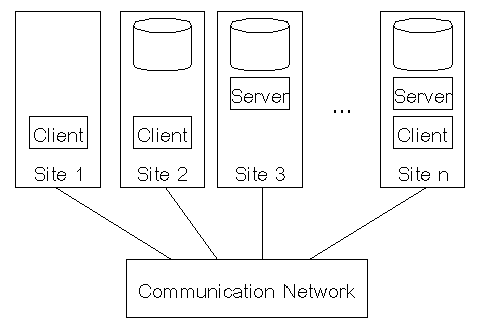
แบ่งออกเป็นสามระดับ
- โปรแกรมส่วน Server รับผิดชอบเกี่ยวกับการจัดการข้อมูล ซึ่งจะเหมือนกับโปรแกรม DBMS แบบรวมศูนย์
- โปรแกรมส่วน Client รับผิดชอบเกี่ยวกับการเข้าถึงข้อมูลที่อยู่ใน DDBMS catalog และทาการร้องขอการใช้บริการข้อมูลไปที่ไซต์อื่น
- โปรแกรมส่วน Communication จะสนับสนุนการสื่อสารข้อมูลบนระบบเครือข่าย ซึ่ง จะถูกใช้งานโดยโปรแกรมส่วน Client เพื่อทำการส่งคำสั่งและข้อมูลไปยังไซต์ที่ต้องการ
สถาปัตยกรรม Client-Server
- เป็นระบบคอมพิวเตอร์ที่ประกอบไปด้วยเครื่องคอมพิวเตอร์จานวนหลาย ๆ เครื่อง ทั้งคอมพิวเตอร์ส่วนบุคคล เวิรค์สเตชัน เครื่องให้บริการแฟ้มข้อมูล
- เครื่องที่ขอใช้บริการ (Client)
- เครื่องให้บริการ (Server)
- Client จะทำหน้าที่ในการสร้างแผนการสืบค้นข้อมูลแบบกระจาย
- ควบคุมให้การทำ Transaction มีคุณสมบัติ ACID อยู่เสมอ
- หน้าที่ที่สาคัญอีกอย่างหนึ่งคือมีความสามารถที่จะซ่อนรายละเอียดของการกระจายของข้อมูลจากผู้ใช้
การประมวลผลคาสั่ง SQL ระหว่าง Client-Server
- Client วิเคราะห์คำสั่ง และแยกคำสั่งออกเป็นหลาย ๆ คำสั่ง ตาม Server Site ที่จะทำการสืบค้นข้อมูล จากนั้นก็จะส่งคาสั่งไปยังแต่ละ Server Site นั้น
- Server แต่ละตัวจะประมวลผลคาสั่งในเครื่องตนเอง และส่งผลลัพธ์กลับไปยัง Client
- Client รวบรวมผลลัพธ์ที่ได้รับกลับมาจากไซต์ต่าง ๆ แล้วสร้างเป็นผลลัพธ์สุดท้าย
- เครื่องที่ทำหน้าที่ประมวลผลคำสั่งจะเรียกว่า Database Process (DP หรือเครื่อง Backend)
- เครื่อง Client จะเรียกว่า Application Processor (AP ) หรือเครื่อง Frontend
ในระบบฐานข้อมูลแบบกระจาย ข้อมูลจะถูกจัดเก็บไว้ในหลาย ๆ ไซต์
- แต่ละไซต์มีระบบจัดการฐานข้อมูลของตนเอง
ความเป็นอิสระของการกระจายของข้อมูล (Distributed Data Independent)
- ผู้ใช้สามารถที่จะสอบถามข้อมูลได้โดยไม่ต้องระบุว่า รีเลชัน หรือสาเนาของรีเลชัน หรือส่วนของรีเลชัน อยู่ที่ไหน
ความถูกต้องในการประมวลผล Transaction แบบกระจาย (Distributed transaction atomicity)
- ผู้ใช้สามารถสร้าง TransactionTransactionที่สามารถเข้าถึงข้อมูลและปรับปรุงข้อมูลที่อ ยู่ที่ไซต์อื่น ๆ ได้ โดยการสร้าง Transaction ที่ไซต์ของตนเองเท่านั้น และ ต้องมีคุณสมบัติ ACID ด้วย
การจัดเก็บข้อมูลในระบบฐานข้อมูลแบบกระจายมีอยู่หลายวิธีด้วยกันคือ
- การทำสำเนา (Replication): เป็นการทาสาเนาของรีเลชันไว้หลายๆ สาเนา และแต่ละสาเนาจะถูกเก็บไว้ต่างไซต์กัน
- การทำสำเนาของรีเลชัน r ไว้หลาย ๆ ไซต์ โดยทั่วไปจะทาการสำเนาแบบ Full Replication นั่นคือจะทาการสร้างสำเนาของรีเลชันกับทุก ๆ ไซต์
- การทำสำเนาช่วยเพิ่มความสะดวกในการสืบค้นข้อมูลของ Transaction แบบอ่านอย่างเดียว อย่างไรก็ตาม Transaction แบบที่มีการปรับปรุงข้อมูลจะต้องมีการดำเนินการที่เพิ่มมากขึ้น
- ข้อดีและข้อเสียดังนี้คือ
- Availability ถ้าไซต์ที่มีรีเลชัน r เกิดหยุดการทางานลง ระบบสามารถที่จะทางานต่อไปได้โดยไปดึงข้อมูล รีเลชัน r ที่ไซต์อื่น โดยไม่ต้องคานึงถึงไซต์ที่หยุดทางานไป
- Increased Parallelism ช่วยลดปริมาณข้อมูลที่จะส่งผ่านระหว่างไซต์ได้
- Increased Overhead on Update สำเนาข้อมูลของรีเลชัน r ในแต่ละไซต์จะต้องเหมือนกันทุก ๆ ไซต์ ไม่เช่นนั้นแล้วการประมวลผลกับรีเลชัน r อาจจะเกิดความผิดพลาดขึ้นได้
- ดังนั้นเมื่อไรก็ตามที่รีเลชัน r ถูกแก้ไข ระบบจะต้องทำการแก้ไขข้อมูลรีเลชัน r ให้ครบทุกไซต์ที่มีรีเลชัน r
- ข้อดีและข้อเสียดังนี้คือ
- การแยกรีเลชัน(Fragmentation): เป็นการแยกรีเลชันออกเป็นหลาย ๆ ส่วน และจัดเก็บแต่ละส่วนไว้ต่างไซต์กัน
- รีเลชัน r จะถูกแบ่งออกเป็นรีเลชันย่อย r^1,r^2,r^3,…,r^n
- เมื่อนำกลับมารวมกันจะได้ผลลัพธ์เป็นรีเลชัน r เหมือนเดิม
- วิธี Replication และ Fragmentation: เป็นการแยกรีเลชันออกเป็นหลาย ๆ ส่วน และแต่ละส่วนก็จะมีการจัดการแบบสำเนา
- เป็นการนาวิธีการทำสำเนาข้อมูล และการแยกข้อมูลมาใช้ร่วมกัน
- รีเลชันย่อย สามารถถูกทำสำเนาได้ และสำเนาของรีเลชันย่อยก็สามารถถูกแยกรีเลชันได้
ข้อดีของระบบจัดการฐานข้อมูลแบบกระจาย
- การกระจายข้อมูลตามลักษณะระบบงาน
- ระบบงานทางด้านฐานข้อมูลบางระบบงานเป็นลักษณะที่ข้อมูลมีการกระจายอยู่ในหลาย ๆ ที่
- เพิ่มความน่าเชื่อ ถือ
- ในระบบฐานข้อมูลแบบกระจายเรามีการจัดเก็บข้อมูลไว้ในหลาย ๆ ไซต์นั่นคือเมื่อ มีไซต์ใดไซต์หนึ่งเกิดความล้มเหลวขึ้น ระบบก็สามารถที่จะไปหาข้อมูลจากไซต์อื่นได้
- การยอมให้มีการใช้ขอมูลร่วมกันได้
- คือในแต่ละไซต์สามารถที่จะยอมให้ผู้ใช้จากไซต์อื่นสามารถเข้าถึงข้อมูล ในขณะที่ไซต์กาลังจัดการกับข้อมูลและโปรแกรม
- ปรับปรุงการทำงาน
- กรณีที่มีข้อมูลมีจำนวนมาก และได้มีการกระจายข้อมูลไว้ในไซต์ต่าง ๆ ในการสืบค้นข้อมูลหรือการทำ Transaction ของแต่ละไซต์ จะสามารถทำได้อย่างรวดเร็ว
ข้อเสีย หรือ หน้าที่ที่เพิ่มขึ้น
- สามารถที่จะติดต่อไปยังไซต์อื่นๆและส่งแบบสอบถามและข้อมูลผ่านทางเครือข่ายคอมพิวเตอร์ได้
- สามารถที่จะเก็บข้อมูลของข้อมูลที่ม ีการกระจาย และข้อมูลที่ม ีการทาสาเนา ไว้ในแคตตาลอก ของ DDBMS ได้
- สามารถวางแผนวิธีการสืบค้นข้อมูล และการทา TransactionTransactionที่มีการใช้ข้อมูลมากกว่า 1 ไซต์
- สามารถตัดสินใจได้ว่าจะเข้าถึงข้อมูลที่ได้มีการสาเนาไว้จากไซต์ไหน
- สามารถที่จะจัดการความสอดคล้องของข้อมูลที่ได้มีการทำสำเนาไว้
- สามารถที่จะกู้คืนข้อมูลจากไซต์ที่ล้มเหลวได้
